运维过程中所接触到的 Linux 命令
前言
话说搞运维的人没有两把“刷子”,都不好意思上服务器操作。
因此想总结下自己运维过程中所接触到的 Linux 命令
不会记录的很详细。想到记录什么就记录什么。
lsb_release
查看Linux系统版本
[root@massive-dataset-new-005 ~]# lsb_release -a
LSB Version: :base-4.0-amd64:base-4.0-noarch:core-4.0-amd64:core-4.0-noarch:graphics-4.0-amd64:graphics-4.0-noarch
Distributor ID: CentOS
Description: CentOS release 6.5 (Final)
Release: 6.5
Codename: Final
uname
查看Linux内核版本命令
[root@massive-dataset-new-005 ~]# uname -a
Linux massive-dataset-new-005 2.6.32-696.16.1.el6.x86_64 #1 SMP Wed Nov 15 16:51:15 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
crontab
查看某个用户的 cron 任务
crontab -u username -l
查看所有用户的 cron 任务
# 以root用户执行
cat /etc/passwd | cut -f 1 -d : |xargs -I {} crontab -l -u {}
bc
bc命令是一种支持任意精度的交互执行的计算器语言。是Linux简单的计算器,能进行进制转换与计算。
执行浮点运算
参数 scale=3 是将bc输出结果的小数位设置为3位
echo "scale=3;10/3" | bc
3.333
进制转换
echo "obase=2;$255" | bc
11111111
ps
查进程有两个命令
- ps -ef
- ps aux
| 上面两个命令都是列出所有的进程,还是通过 | 管道和 grep 来过滤掉想要查的进程 |
比如说 ps -ef | grep java
把进程查出来干嘛?知道它的进程ID了,可以把他给杀掉
kill -9 processId 杀掉某个进程
netstat
查端口也是一个很常见的操作
常见命令 netstat -lntup
查看当前所有 tcp/udp 端口的信息
lsof
查看某个端口详细的信息 lsof -i:4000
tail
最常用的 tail -f
tail -300f shopbase.log # 倒数300行并进入实时监听文件写入模式
grep
在文件中搜索字符串匹配的行并输出
grep forest f.txt # 文件查找
grep forest f.txt cpf.txt # 多文件查找
grep 'log' /home/admin -r -n # 目录下查找所有符合关键字的文件
grep ERROR */* 搜索当前路径下所有的文件
cat f.txt | grep -i shopbase # -i 不区分大小写 -v 排除指定字符串
grep 'shopbase' /home/admin -r -n --include *.{vm,java} # 指定文件后缀
grep 'shopbase' /home/admin -r -n --exclude *.{vm,java} # 反匹配
seq 10 | grep 5 -A 3 #上匹配 显示匹配后和它后面的3行
seq 10 | grep 5 -B 3 #下匹配 显示匹配行和它前面的3行
seq 10 | grep 5 -C 3 #上下匹配,平时用这个就妥了 匹配行和它前后各3行
cat f.txt | grep -c 'SHOPBASE' # -c 统计文件中某字符串的个数
比如在面对比较大的日志文件查看时,用 grep 来更好。
grep 13888888888 service.log -C 30 | less
这么一搞,就能将 service.log 中所有含有 13888888888 的记录上下 30 行给搜出来,搜索的速度还是贼快的。
awk
内建变量
NR: NR表示从awk开始执行后,按照记录分隔符读取的数据次数,默认的记录分隔符为换行符 因此默认的就是读取的数据行数,NR可以理解为Number of Record的缩写。
FNR: 在awk处理多个输入文件的时候,在处理完第一个文件后,NR并不会从1开始,而是继续累加
因此就出现了FNR,每当处理一个新文件的时候,FNR就从1开始计数,FNR可以理解为File Number of Record。
NF: NF表示目前的行记录用分割符分割的字段的数目,NF可以理解为Number of Field。
基本命令
默认分隔符为空白字符(tab、空格)
awk '{print $4,$6}' f.txt # 第4、5列
awk '{print NR,$0}' f.txt cpf.txt # 以行号输出,行号累加、$0 表示整行、多个文件
awk '{print FNR,$0}' f.txt cpf.txt # 每个文件的行号从1开始计算
awk '{print FNR,FILENAME,$0}' f.txt cpf.txt # FILENAME 多文件匹配时输出该行所在的文件名
awk '{print FILENAME,"NR="NR,"FNR="FNR,"$"NF"="$NF}' f.txt cpf.txt # NF 分割字段数
echo 1:2:3:4 | awk -F: '{print $1,$2,$3,$4}' # -F 指定分割符
匹配
awk '/ldb/ {print}' f.txt #匹配ldb
awk '!/ldb/ {print}' f.txt #不匹配ldb
awk '/ldb/ && /LISTEN/ {print}' f.txt #匹配ldb和LISTEN
awk '$5 ~ /ldb/ {print}' f.txt #第五列匹配ldb
find
sudo -u admin find /home/admin /tmp /usr -name "*.log" (多个目录去找)
find . -iname "*.txt" (大小写都匹配)
find . -type d (当前目录下的所有子目录)
find /usr -type l (目录下所有的符号链接)
find /usr -type l -name "z*" (目录下符合z开头的符号链接)
find /usr -type l -name "z*" -ls (符号链接的详细信息 eg:inode,目录)
find /home/admin -size +250000k(超过250000k的文件,当然+改成-就是小于了)
find /home/admin -tyep f -perm 777 (按照权限查询文件)
find /home/admin -tyep f -perm 777 -ls (按照权限查询文件)
find /home/admin -type f -perm 777 -exec ls -l {} \; (按照权限查询文件)
find /home/admin -atime -1 1天内访问过的文件
find /home/admin -ctime -1 1天内状态改变过的文件
find /home/admin -mtime -1 1天内修改过的文件
find /home/admin -amin -1 1分钟内访问过的文件
find /home/admin -cmin -1 1分钟内状态改变过的文件
find /home/admin -mmin -1 1分钟内修改过的文件
find /home/admin -newer while2 -type f -exec ls -l {} \; # 搜索比 while2 文件更新的且类型是普通文件的文件,搜索到时打印该文件的信息
top
top 命令查看进程的状态
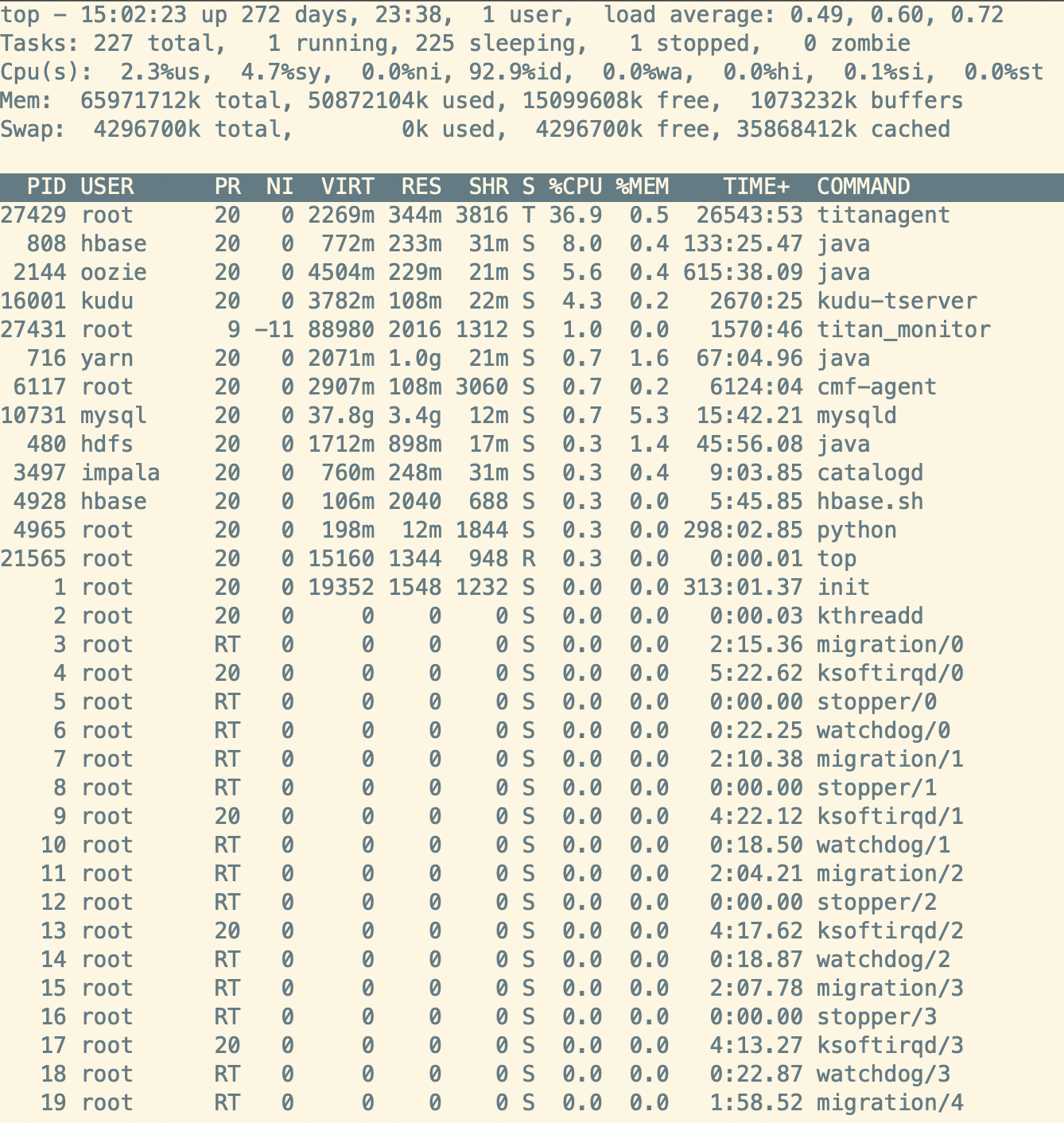
第一行: 系统运行时间和平均负载
当前时间、系统已运行时间、当前登录用户的数量、最近5、10、15分钟内的平均负载
其中有个 load average 可能不是那么好理解。
load average: 在特定时间间隔内运行队列中(在CPU上运行或者等待运行多少进程)的平均进程数。
load average 有三个值,分别代表:1分钟、5分钟、15分钟内运行进程队列中的平均进程数量。
- 正在运行的进程 + 准备好等待运行的进程 在特定时间内(1分钟,5分钟,10分钟)的平均进程数
load average 数据是每隔5秒钟检查一次活跃的进程数
Linux进程可以分为三个状态
- 阻塞进程
- 可运行的进程
- 正在运行的进程
比如现在系统有2个正在运行的进程,3个可运行进程,那么系统的 load 就是5,load average 就是一定时间内的 load 数量均值。
第二行: 任务
任务的总数、运行中(running)的任务、休眠(sleeping)中的任务、停止(stopped)的任务、僵尸状态(zombie)的任务
第三行: cpu状态
| 字段 | 字段释义 |
|---|---|
| us | user: 运行(未调整优先级的) 用户进程的CPU时间 |
| sy | system: 运行内核进程的CPU时间 |
| ni | niced: 运行已调整优先级的用户进程的CPU时间 |
| id | idle: 空闲时间 |
| wa | IO wait: 用于等待IO完成的CPU时间 |
| hi | 处理硬件中断的CPU时间 |
| si | 处理软件中断的CPU时间 |
| st | 这个虚拟机被 hypervisor 偷去的CPU时间 |
注意: 对于st中,如果当前处于一个 hypervisor 下的vm,实际上 hypervisor 也是要消耗一部分CPU处理时间的
第四行: 内存
全部可用内存、已使用内存、空闲内存、缓冲内存
第五行: swap
全部、已使用、空闲和缓冲交换空间
第七行之后
PID 进程ID,进程的唯一标识符
USER 进程所有者的实际用户名
PR 进程的调度优先级。这个字段的一些值是’rt’。这意味这这些进程运行在实时态。
NI 进程的nice值(优先级)。越小的值意味着越高的优先级。负值表示高优先级,正值表示低优先级
VIRT virtual memory usage 虚拟内存,进程使用的虚拟内存
进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
1 进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等
2 假如进程申请100m的内存,但实际只使用了10m,那么它会增长100m,而不是实际的使用量
RES resident memory usage 常驻内存,驻留内存大小
驻留内存是任务使用的非交换物理内存大小。进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
1 进程当前使用的内存大小,但不包括swap out
2 包含其他进程的共享
3 如果申请100m的内存,实际使用10m,它只增长10m,与VIRT相反
4 关于库占用内存的情况,它只统计加载的库文件所占内存大小
SHR shared memory 共享内存 1 除了自身进程的共享内存,也包括其他进程的共享内存 2 虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小 3 计算某个进程所占的物理内存大小公式:RES – SHR 4 swap out后,它将会降下来
S 这个是进程的状态
- D - 不可中断的睡眠态。
- R – 运行态
- S – 睡眠态
- T – 被跟踪或已停止
- Z – 僵尸态
%CPU 自从上一次更新时到现在任务所使用的CPU时间百分比。
%CPU显示的是进程占用一个核的百分比,而不是整个cpu(N核)的百分比,有时候可能大于100,那是因为该进程启用了多线程占用了多个核心,所以有时候我们看该值得时候会超过100%,但不会超过总核数*100
%MEM 进程使用的可用物理内存百分比
TIME+ 任务启动后到现在所使用的全部CPU时间,精确到百分之一秒
COMMAND 运行进程所使用的命令。进程名称(命令名/命令行)
交互命令
top 运行中可以通过 top 的内部命令对进程的显示方式进行控制。
按”h”或者”?”, 会显示帮助
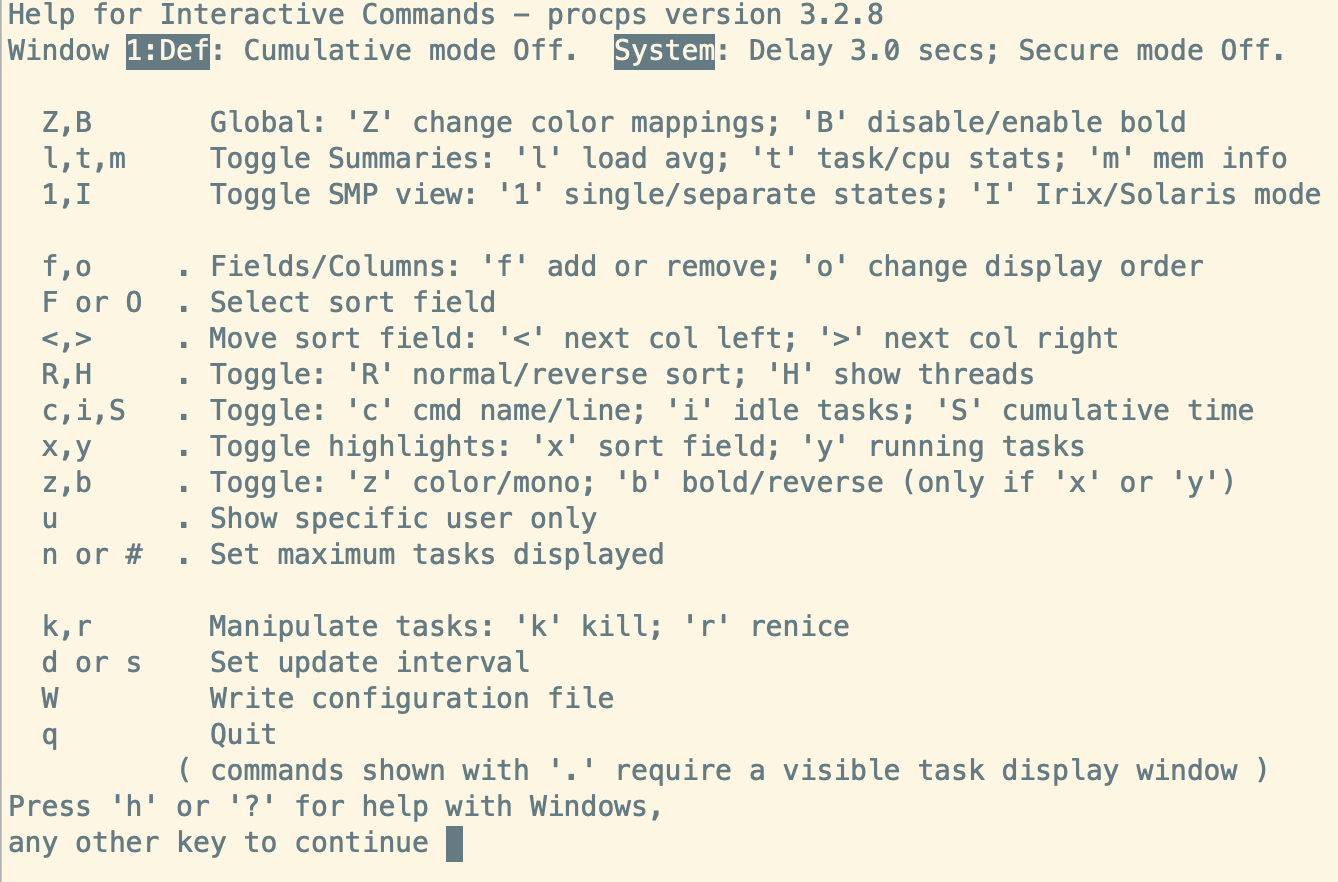
内部命令如下:
- s – 改变画面更新频率 – 常用
- M – 以内存占用率大小的顺序排列进程列表 – 常用
- P – 以 CPU 占用率大小的顺序排列进程列表 – 常用
- N – 以 PID 的大小的顺序排列表示进程列表
- R - 正常排序/反向排序
- l – 关闭或开启第一部分第一行 top 信息的表示
- t – 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示
- m – 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示
- n – 设置在进程列表所显示进程的数量
- c - 切换显示命令名称和完整命令行
- u - 输入用户,显示用户的任务
- i - 忽略闲置和僵死进程, 这是一个开关式命令
- 1 - 监控每个逻辑CPU的状况 – 常用
- q – 退出 top – 常用
常用参数与命令
- d - 指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变之
- p - 通过指定监控进程ID来仅仅监控某个进程的状态
- H - 设置线程模式。在设置线程模式下,第二行的tasks指的是线程个数
配合来查询进程的各种问题了
1 如下显示某个进程所有活跃的线程消耗情况
ps -ef | grep java
top -H -p pid
按f、再按j把P调出来,按回车确认
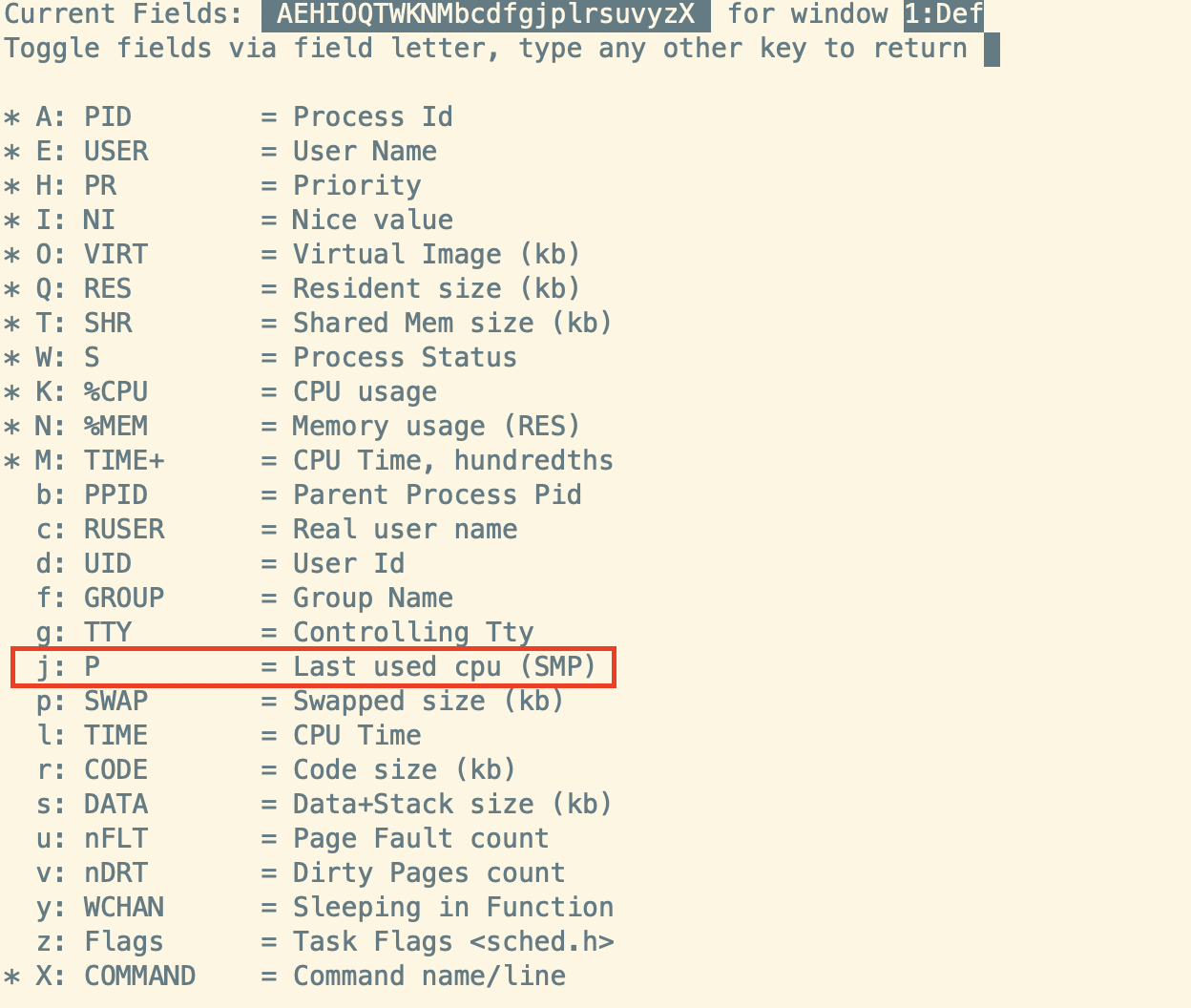
P代表”Last used CPU”, 表示上一次运行在哪个CPU内核上
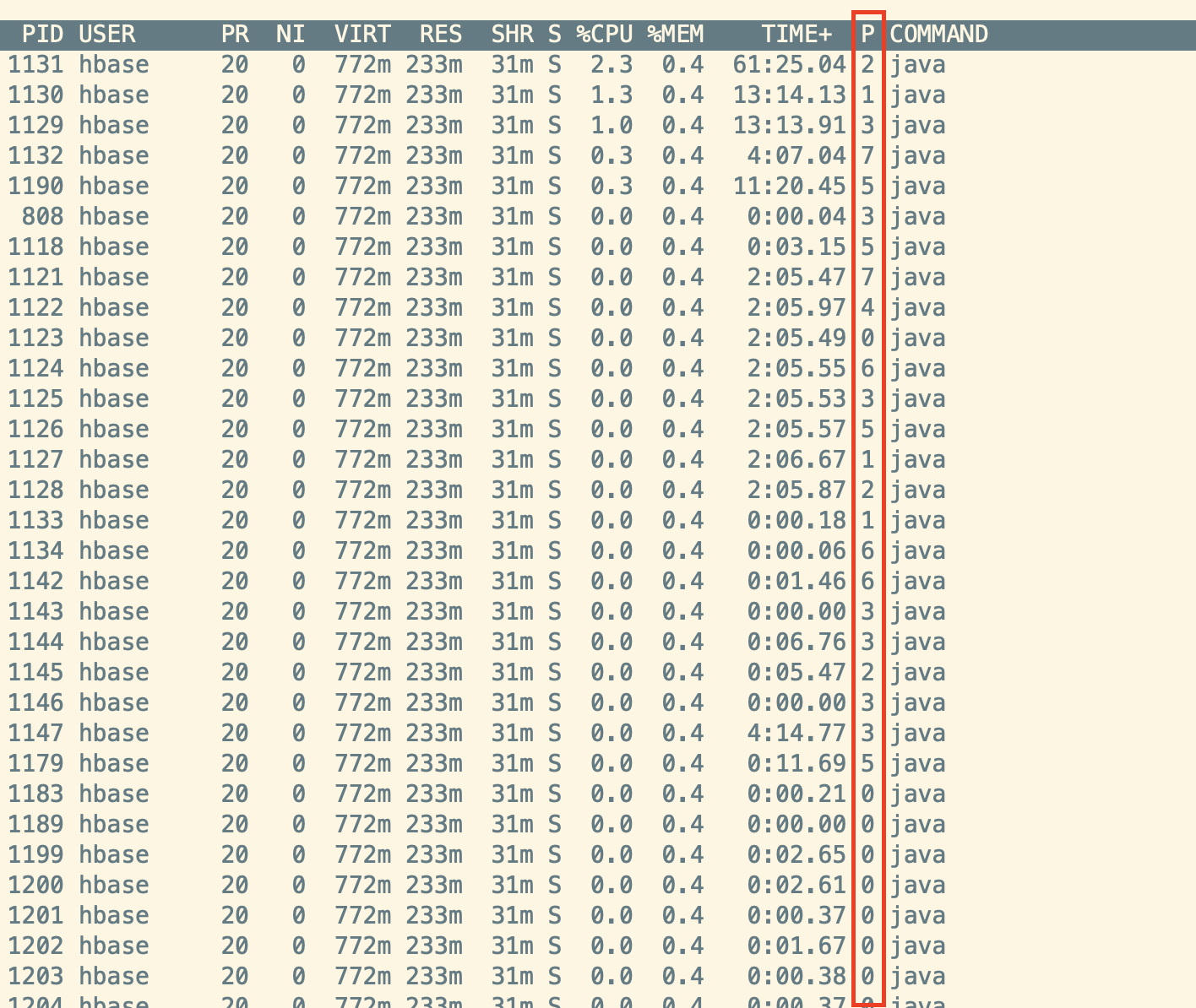
2 排查一些进程内线程状态,top -H -p pid获得线程10进制转16进制后 jstack 去抓看这个线程到底在干啥 使用堆栈进行问题排查
free
查看内存使用状况
包括系统物理内存、虚拟内存(swap 交换分区)、共享内存和系统缓存的使用情况。
其输出和 top 命令的内存部分非常相似。
命令常用的选项及各自的含义
- -b 以 Byte(字节)为单位,显示内存使用情况。
- -k 以 KB 为单位,显示内存使用情况,此选项是 free 命令的默认选项。
- -m 以 MB 为单位,显示内存使用情况。
- -g 以 GB 为单位,显示内存使用情况。
- -t 在输出的最终结果中,输出内存和 swap 分区的总量。
- -o 不显示系统缓冲区这一列。
- -s 间隔秒数 根据指定的间隔时间,持续显示内存使用情况。

第一行显示的是各个列的列表头信息,各自的含义如下所示:
- total 是总内存数
- used 是已经使用的内存数
- free 是空闲的内存数
- shared 是多个进程共享的内存总数
- buffers 是缓冲内存数
- cached 是缓存内存数
Mem 一行指的是内存的使用情况
-/buffers/cache 的内存数,相当于第一行的 used-buffers-cached
+/buffers/cache 的内存数,相当于第一行的 free+buffers+cached
Swap 一行指的就是 swap 分区的使用情况
可以看到,系统的物理内存为 62 GB,已经使用了 48 GB,空闲 14 GB。
而 swap 分区总大小为 4 GB,目前尚未使用。
Linux 的内存管理机制的思想包括(不敢说就是)内存利用率最大化,内核会把剩余的内存申请为 cached,而 cached 不属于 free 范畴。
如果 free 的内存不够,内核会把部分 cached 的内存回收,回收的内存再分配给应用程序。
所以对于linux系统,可用于分配的内存不只是free的内存,还包括cached的内存(其实还包括buffers)
可用内存 = free的内存 + cached的内存 + buffers。也就是+/buffers/cache 的内存数的数值
Free 中的 buffer 和 cache,它们都是占用内存
buffers: 作为 buffer cache 的内存,是块设备的读写缓冲区。用于CPU和内存之间的缓冲
cached: 作为 page cache 的内存, 文件系统的 cache。用于内存和硬盘的缓冲
Buffer Cache 和 Page Cache。前者针对磁盘块的读写,后者针对文件 inode 的读写。这些Cache有效缩短了 I/O系统调用(比如read,write,getdents)的时间。磁盘的操作有逻辑级(文件系统)和物理级(磁盘块)
iostat
iostat 是 I/O statistics(输入/输出统计)的缩写。
iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析。
iostat 常用命令格式 iostat [参数] [时间] [次数]
命令参数说明如下:
- -c 显示CPU使用情况
- -d 显示磁盘使用情况
- -k 以K为单位显示
- -m 以M为单位显示
- -N 显示磁盘阵列(LVM) 信息
- -n 显示NFS使用情况
- -p 可以报告出每块磁盘的每个分区的使用情况
- -t 显示终端和CPU的信息
- -x 显示详细信息
使用示例iostat -x 3
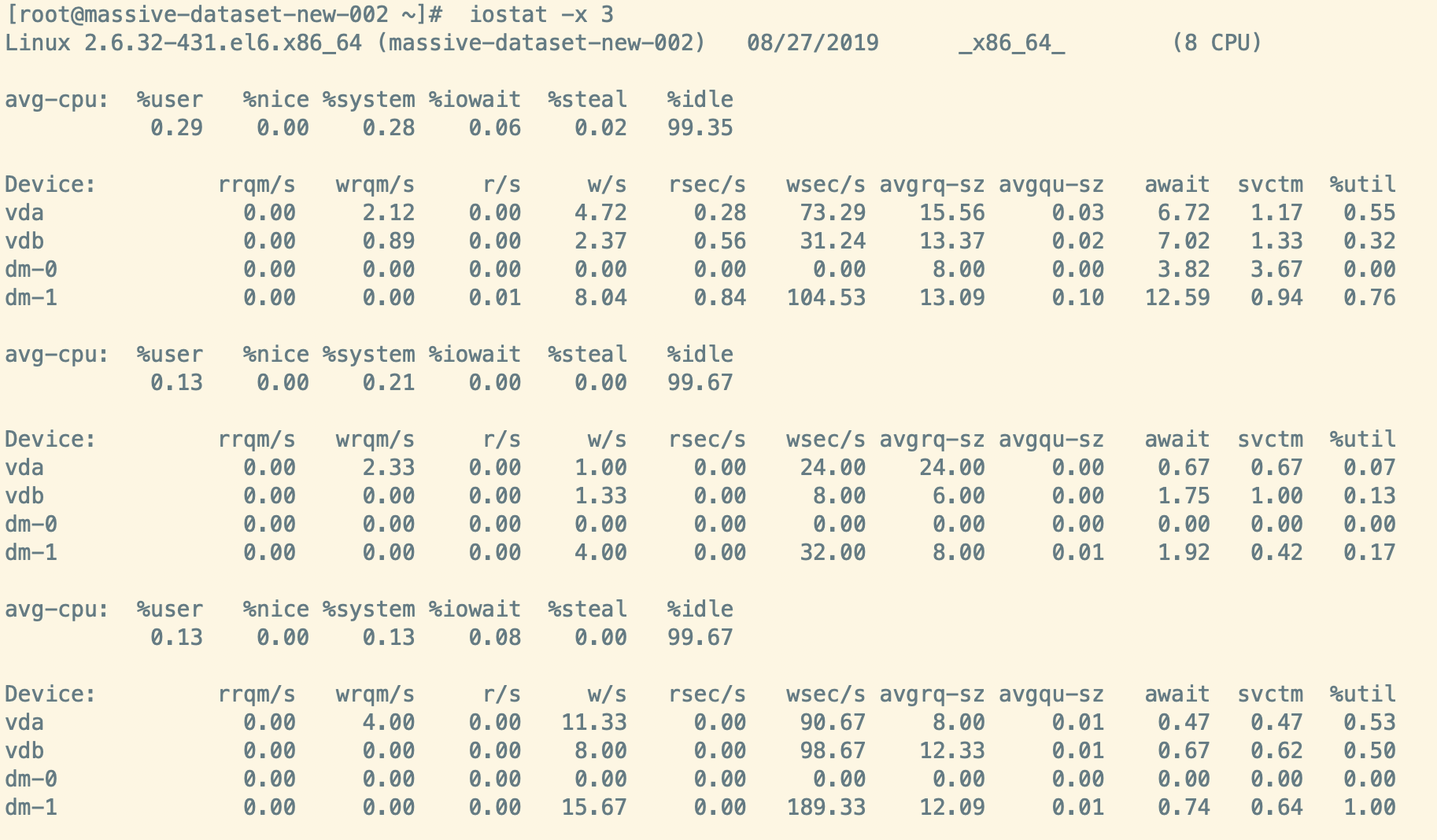
在日常运维中到底需要关注哪些字段呢?到底该关注哪些输出内容就可以确定这台服务器是否存在IO性能瓶颈。
%iowait: 如果该值较高,表示磁盘存在I/O瓶颈
await: 一般地,系统I/O响应时间应该低于5ms,如果大于10ms就比较大了
avgqu-sz: 如果I/O请求压力持续超出磁盘处理能力,该值将增加。如果单块磁盘的队列长度持续超过2,一般认为该磁盘存在I/O性能问题。需要注意的是,如果该磁盘为磁盘阵列虚拟的逻辑驱动器,需要再将该值除以组成这个逻辑驱动器的实际物理磁盘数目,以获得平均单块硬盘的I/O等待队列长度
%util: 一般地,如果该参数是100%表示设备已经接近满负荷运行了
具体使用参考自Linux iostat命令详解
fdisk
fdisk -l 显示当前分区情况
参考链接