本文大部分内容都是转载于 AlstonWilliams 的HBase Data Block Encoding Types介绍,其中穿插些自己理解和认为的内容。
前言
为什么需要 Data Block Encoding Types
这里简单介绍一下HFile的组成,让读者知道什么是 Data Block Encoding.
HFile 中,包含了好几个部分,具体的请查看HFile Format.
这里只关心 HFile 里的 Data Block.
HFile 在存储每一个 Row 时,不是把这一条 Row 的全部 Family/Column 整合成在一起,保存起来的,如下:
RowKey | Family:Column1 -> value | Family:Column2 -> value
它是把这条 Row,根据 Column 拆分成好几个 KeyValue,保存起来的,如下:
RowKey/Family:Column1 -> value
RowKey/Family:Column2 -> value
我们可以看到,RowKey 需要重复保存很多次,而且 Family:Column 这个往往都是非常相似的,它也需要保存很多次.这对磁盘非常不友好. 当 Family:Column 越多时,就需要占用越多不必要的磁盘空间.
如果仅仅是磁盘空间,也没什么关系,毕竟我们可以通过 Snappy/GZ 等压缩方式,对 HFile 进行 Compression.而且磁盘又便宜,对吧?
可是,对 HBase 熟悉的读者,都知道,当读取数据时,读取的数据会缓存在 BlockCache 中的.那我们的 Block 越小,能放到 BlockCache 中的数据就越多,命中率就越高,对 Scan 就越友好.
Block Encoding 就是做这件事情的,它就是通过某种算法,对 Data Block 中的数据进行压缩,这样 Block 的 Size 小了,放到 BlockCache 中的就多了.
这儿提出两个问题:
- 压缩以后,占的 Disk/Memory 是少了,但是解压的时候,需要更多的CPU时间.如何均衡呢?
- 如果我们的业务,偏重的是随机 Get,那放到 Block Cache 中不一定好吧?不仅放到 Block Cache 中的 Block 很容易读不到,对性能并没有什么提升,还会产生额外的开销, 比如将其它偏重 Scan 的业务的Block排挤出 Block Cache,导致其它业务变慢.
块压缩
HBase 中提供了五种 Data Block Encoding Types,具体有:
- NONE
- PREFIX
- DIFF
- FAST_DIFF
- PREFIX_TREE
NONE这种就不介绍了,这个很容易理解。
PREFIX
一般来说,同一个Block中的Key(KeyValue中的Key,不仅包含RowKey,还包含Family:Column),
都很相似.它们往往只是最后的几个字符不同.
例如,KeyA是RowKey:Family:Qualifier0,
跟它相邻的下一个KeyB可能是RowKey:Family:Qualifier1.
在PREFIX中,相对于NONE,会额外添加一列,表示当前key(KeyB)和它前一个key(KeyA), 相同的前缀的长度(记为PrefixLength).在上面的例子中,如果KeyA是这个Block中的第一个key, 那它的PrefixLength就是0.而KeyB的PrefixLength是23.
很明显,如果相邻 Key 之间,完全没有共同点,那 PREFIX 显然毫无用处,还增加了额外的开销.
下面一些 Row,当使用 NONE 这种 Block Encoding时,如下图所示:
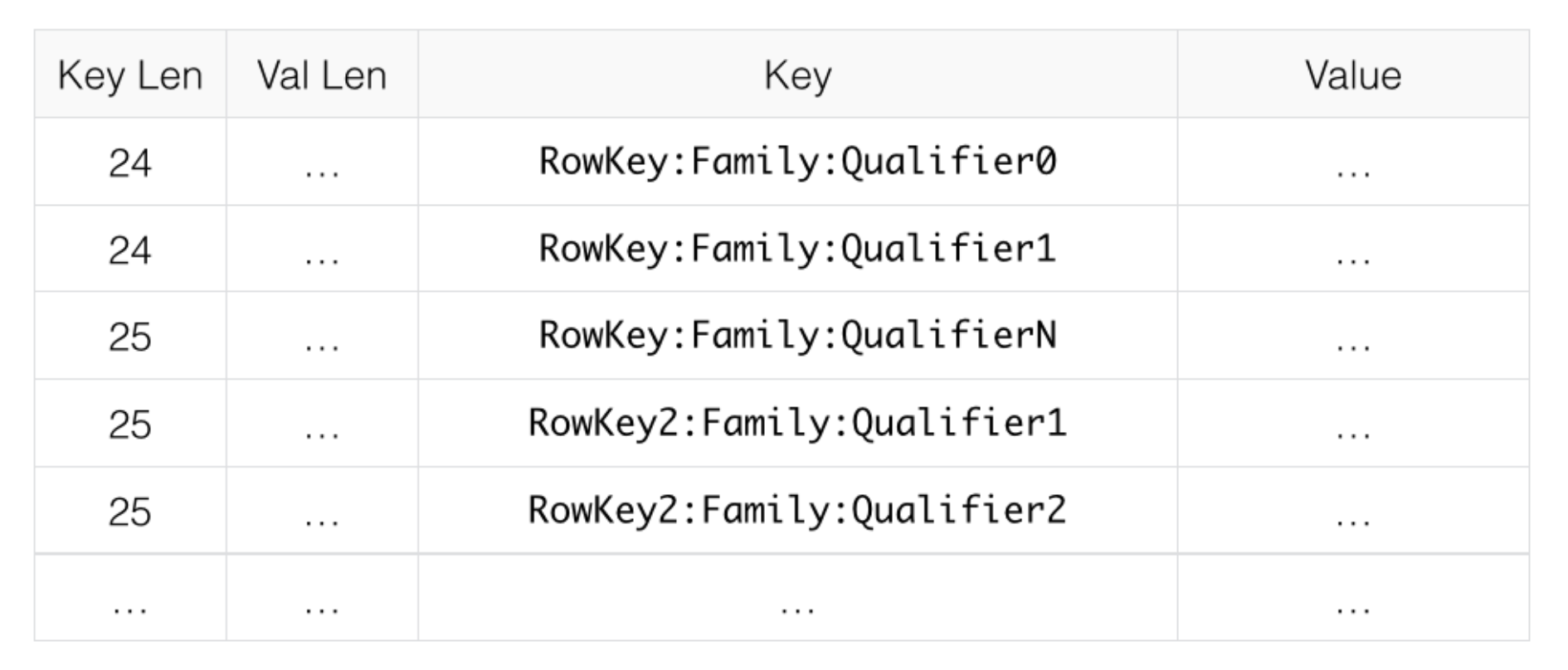
而如果采用 PREFIX 这种数据块编码,如下图所示:

DIFF
DIFF 是对 PREFIX 的一种改良.不在把 Key 看成单个字节序列,而是分割每个字段,对每字段进行压缩,提高效率。
它添加了两个新的字段,timestamp 和 type.
如果 KeyB 的 ColumnFamily、key length、value length、Key type 和 KeyA 对应字段相同,那么它就会在 KeyB 中被省略.
此外,timestamp 存储的是相对于前一行 Row 的 timestamp 偏移量,而不是完整存储。
默认情况下,DIFF 是不启用的.因为它会导致写数据,以及 Scan 数据更慢.但是,相对于 PREFIX/NONE,它会在 BlockCache 中缓存更多数据.
用 DIFF 编码方式压缩之前的 block 如下图所示:

示例中的第一第二两个行键,并给出时间戳和相同类型的精确匹配,第二行的 value length 或 type 都不需要存储,第二行的时 timestamp 只有0,而不是一个完整的 timestamp。
FAST_DIFF
FAST_DIFF跟DIFF非常相似,所不同的是,它额外增加了一个字段,表示 RowB 是否跟 RowA 完全一样,如果是的话,那数据就不需要重复保存了.
如果在你的场景下,Key很长,或者有很多Column,那么推荐使用FAST_DIFF.
数据格式几乎与 DIFF 编码相同,因此没有图像来说明它。
PREFIX_TREE
PREFIX_TREE 是0.96 中引入的.它大致跟 PREFIX,DIFF,FAST_DIFF 相同,但是它可以让随机读操作,比其它的几种更快.
当然,代价是,memStore 写入到 HFile 时,需要进行更加复杂的 Encoding 操作,所以会更慢。
(AlstonWilliams译者疑问:那Decoding的时候也会更慢啊,而且随机读的话,Block很可能不存在于Block Cache中,那开销主要都在Decoding的时候,所以随机读操作不应该是更慢么?).
PREFIX_TREE 适合于那种 Block Cache 命中率非常高的场景(AlstonWilliams译者注:-.-!).它增加了一个叫做tree的字段.这个字段会保存指向这一Row中, 全部Cell的索引.这对压缩更加友好。
详情请查看 HBASE-4676 以及 Trie
PREFIX_TREE 可能存在些问题。它已在 HBase-2.0.0 中删除。
本人在学习过程中有搜到因使用 PREFIX_TREE 这种 Block Encoding 发生的故障案例:
如何选择 Block Encoding Type?
要使用的压缩或编解码器类型取决于数据的特征。选择错误的类型可能会导致数据占用更多空间而不是更少,并且可能会影响性能。
通常,您需要在较小尺寸和较快压缩/解压缩之间权衡您的选择。
- 如果 Key 很长(与 Value 相比),或者有很多Column,那么推荐使用 FAST_DIFF
- 如果数据是冷数据,不经常被访问,那么使用 GZIP 压缩格式.因为虽然它比 Snappy/LZO 需要占用更多而 CPU,但是它的压缩比率更高,更节省磁盘.
- 如果是热点数据,那么使用Snappy/LZO压缩格式.它们相比GZIP,占用的CPU更少.
- 在大多数情况下,Snappy/LZO的选择都更好.
- Snappy比LZO更好
这里都是针对 Key 的压缩。如果 Value 很大(而不是预压缩,例如图像),请使用 Block Compressors。
总结
本文主要翻译自HBase官方文档
因公司使用的是 1.2.x HBase 版本所以有需求可以阅读下1.2.x 版本的HBase官方文档
这里推荐三篇关于不同Block Encoding Type以及压缩算法对磁盘以及性能有什么影响的文章.
- HBase - Compression vs Block Encoding
- The Effect of ColumnFamily, RowKey and KeyValue Design on HFile Size
- HBase最佳实践-列族设计优化
参考链接