天上那么多星,你可否数得清?
前言
在互联网企业中,经常会有这样的一些需求,比如说:统计下某网站某日pv/uv量或是统计下某签约作者某篇文章的所获点赞数等等类似的需求,
传统的做法可能需要我们先读出该列的原有值,然后+1后再覆盖原有值,同时还要加锁处理等等。
为了保证原子性的完成一个客户端请求,HBase 引入了计数器的概念。本文主要简要概述一下 HBase 计数器的使用及应注意的一些问题。
概念介绍
-
HBase 计数器是什么?
一个计数器就是一个与其他列类似的简单列,列值要求且必须以长整型转码插入,否则将破坏该计数器结构。用户可以一次更新多个计数器,但它们都必须属于同一行。更新多行的计数器需多次RPC请求调用,暂不支持 batch(Increment)。 -
HBase 计数器解决什么问题?
HBase 计数器的引入主要解决了 read-and-modify 场景下的锁竞争与原子性问题。
Shell Api
1. 创建计数器并插入值
注意:步长值可为正可为负可为0.
hbase(main):003:0> incr 'test','r1','f:count',1
COUNTER VALUE = 1
0 row(s) in 0.0790 seconds
hbase(main):004:0> incr 'test','r1','f:count',2
COUNTER VALUE = 3
0 row(s) in 0.0200 seconds
hbase(main):005:0> incr 'test','r1','f:count',-1
COUNTER VALUE = 2
0 row(s) in 0.0170 seconds
2. Get Api 获取计数器值
可见:一个计数器就是一个与其他列类似的简单列。
hbase(main):006:0> get 'test','r1','f:count'
COLUMN CELL
f:count timestamp=1552830973949, value=\x00\x00\x00\x00\x00\x00\x00\x02
1 row(s) in 0.0600 seconds
hbase(main):007:0> get 'test','r1','f:count:toLong'
COLUMN CELL
f:count timestamp=1552830973949, value=2
1 row(s) in 0.0070 seconds
3. 标准 Api 获取计数器值
hbase(main):008:0> get_counter 'test','r1','f:count'
COUNTER VALUE = 2
4. 错误示范
如下操作将破坏计数器结构。
# 以字符串类型PUT值
hbase(main):009:0> put 'test','r1','f:count','123'
0 row(s) in 0.0950 seconds
# GET 获取值正常(该计数器已转为普通列)
hbase(main):010:0> get 'test','r1','f:count'
COLUMN CELL
f:count timestamp=1552831549637, value=123
1 row(s) in 0.0160 seconds
# 执行计数器 get_counter 操作
hbase(main):011:0> get_counter 'test','r1','f:count'
ERROR: offset (0) + length (8) exceed the capacity of the array: 3
# 执行计数器 incr 操作
hbase(main):012:0> incr 'test','r1','f:count',-1
ERROR: org.apache.hadoop.hbase.DoNotRetryIOException: Field is not a long, it's 3 bytes wide
at org.apache.hadoop.hbase.regionserver.HRegion.getLongValue(HRegion.java:7690)
at org.apache.hadoop.hbase.regionserver.HRegion.applyIncrementsToColumnFamily(HRegion.java:7644)
at org.apache.hadoop.hbase.regionserver.HRegion.doIncrement(HRegion.java:7530)
at org.apache.hadoop.hbase.regionserver.HRegion.increment(HRegion.java:7487)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.increment(RSRpcServices.java:592)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.mutate(RSRpcServices.java:2246)
at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:32383)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2150)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:112)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:187)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:167)
可以看出,计数器对数据类型是极其敏感的,使用过程中一定要注意。
Java Api
1. 编码与解码
1) 编码:Bytes.toBytes(long)
2) 解码:Bytes.toLong(bytes)
2. 单列计数器
{
Table table = ...; // 表实例
String rowkey = ...; // 行键
String columnFamily = ...; // 列族
table.incrementColumnValue(Bytes.toBytes(rowkey),Bytes.toBytes(columnFamily), Bytes.toBytes(counter), 1L);
table.close();
}
3. 多列计数器
{
Table table = ...; // 表实例
String rowkey = ...; // 行键
String columnFamily = ...; // 列族
Increment increment = new Increment(Bytes.toBytes(rowkey));
increment.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("pv"), 6L);
increment.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("uv"), 10L);
Result result = table.increment(increment);
table.close();
}
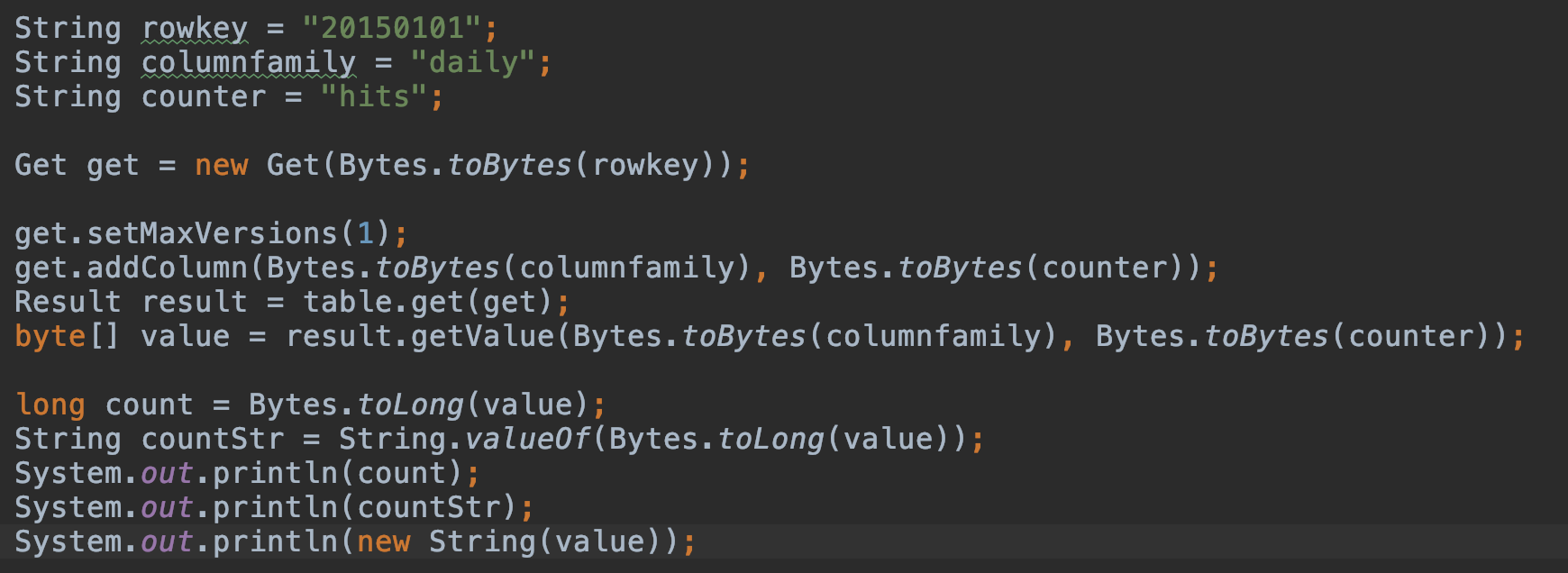
4. 获取计数器的值
Get get = new Get(Bytes.toBytes(rowkey));
get.setMaxVersions(1);
get.addColumn(Bytes.toBytes(columnfamily), Bytes.toBytes(counter));
Result result = table.get(get);
byte[] value = result.getValue(Bytes.toBytes(columnfamily), Bytes.toBytes(counter));
long count = Bytes.toLong(value);
String countStr = String.valueOf(Bytes.toLong(value));
HBase-Hive 映射表
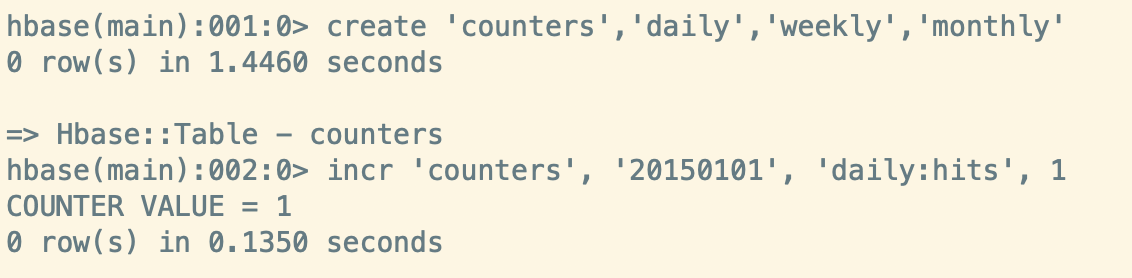
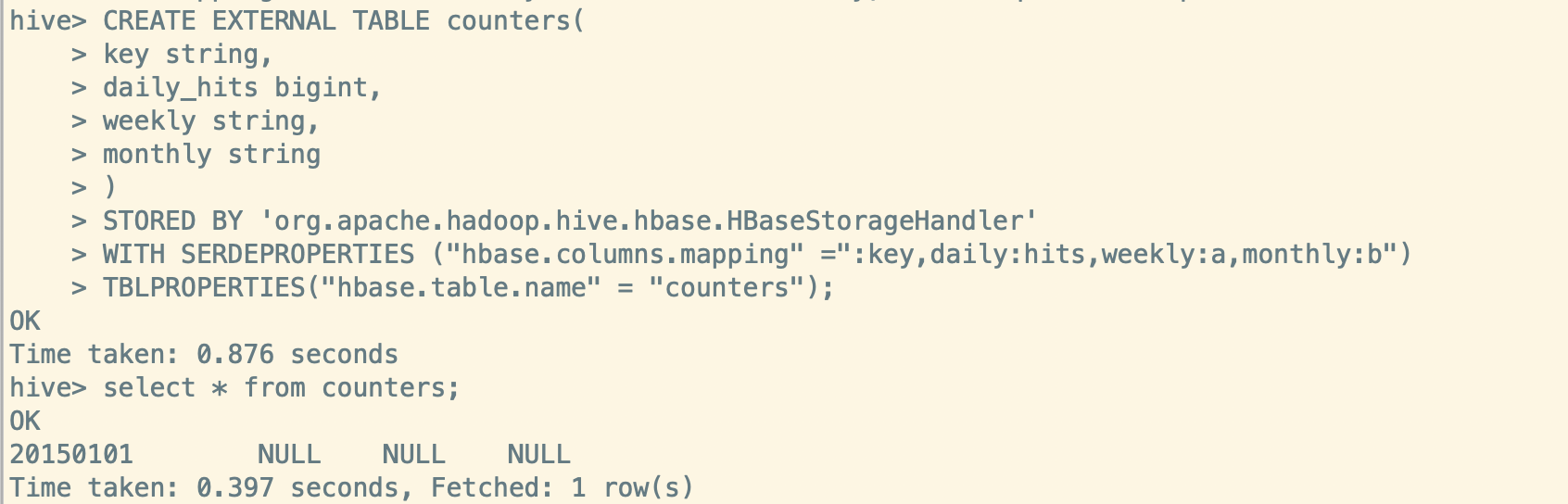
这里需要注意一下,如果想通过 Hive 映射 HBase 表获取计数器的值, 建表语句中计数器列语法要有别于常规列,否则将返回乱码或NULL值。
下面提供一个简单的示例:
CREATE EXTERNAL TABLE counters(
key string,
daily_hits bigint,
weekly string,
monthly string
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
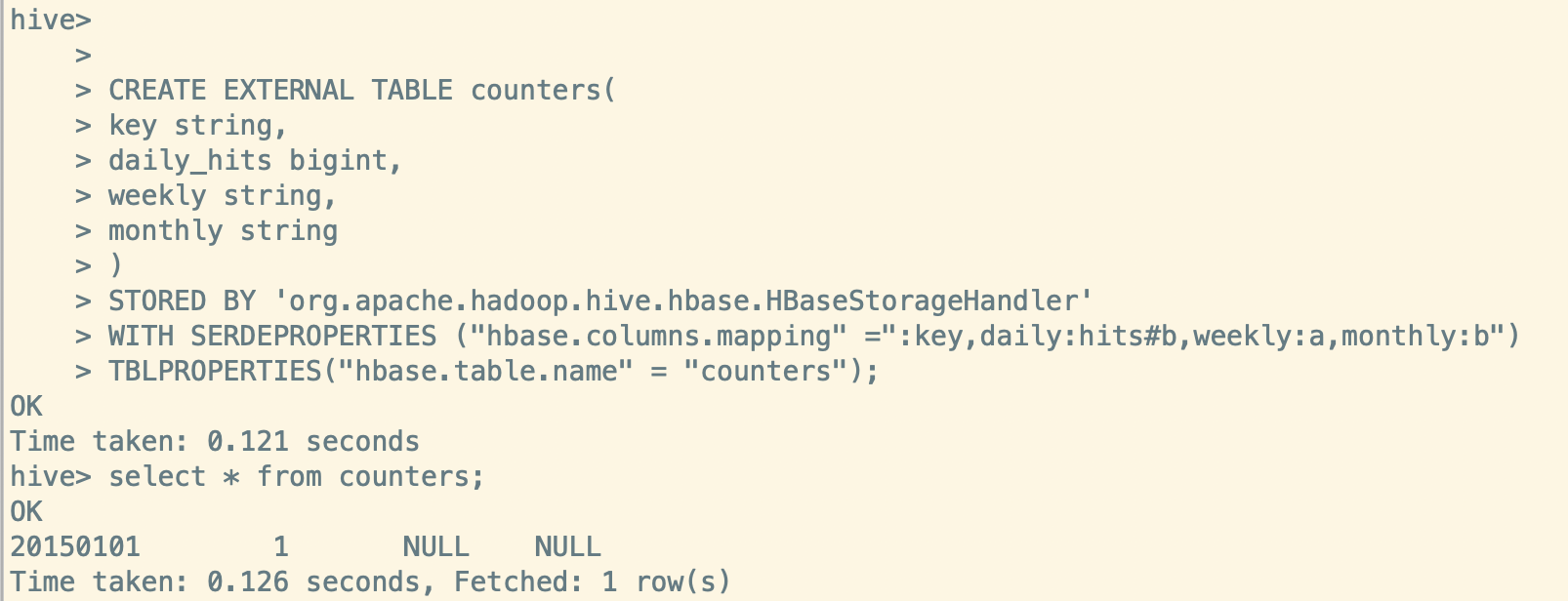
WITH SERDEPROPERTIES ("hbase.columns.mapping" =":key,daily:hits#b,weekly:a,monthly:b")
TBLPROPERTIES("hbase.table.name" = "counters");
当 HBase 中 double,int,long 类型以byte方式存储时,用字符串取出来必然是乱码。

Bytes类型的数据,建 hive 映射表示加 #b
创建 HBase 表,计数器加1
创建 Hive 映射表没有 #b, select 查询为 NULL,错误
创建 Hive 映射表使用 #b, select 查询为 1,正确
当在 Hive 中创建 HBase 已经存在的外部表时,默认的 hbase.table.default.storage.type 类型为 string。
daily_hits 为 bigint 字段的话,映射过来的值为 NULL。也可以修改 hbase.table.default.storage.type 为 binary
CREATE EXTERNAL TABLE HisDiagnose(
key string,
doctorId int,
patientId int,
description String,
rtime int
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" = ":key,diagnoseFamily:doctorId,diagnoseFamily:patientId,diagnoseFamily:description,diagnoseFamily:rtime",
"hbase.table.default.storage.type"="binary"
)
TBLPROPERTIES("hbase.table.name" = "HisDiagnose");
修改 hbase.table.default.storage.type 为 binary之后如果想表示类型为string, 加 cf:val#s 即可。
对此感兴趣可以阅读参考链接hive与hbase数据类型对应关系, hive创建外部表映射hbase中已存在表问题
作者: 禅克
出处: <https://mp.weixin.qq.com/s/EmG57gIJtyLZlYPwdHWNfA>
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在页面明显位置给出原文链接。
参考链接