本文主要描述如何将图片文件转成 sequence file,然后保存到 HBase
前言
HBase 可用于来数据文件。假设我们碰到的是图片文件呢,该如何保存或存储呢。
本文主要描述如何将图片文件转成sequence file,然后保存到HBase。
步骤
-
文件处理流程
-
准备上传文件的Java代码
-
运行代码
-
读HBase并本地输出
处理流程
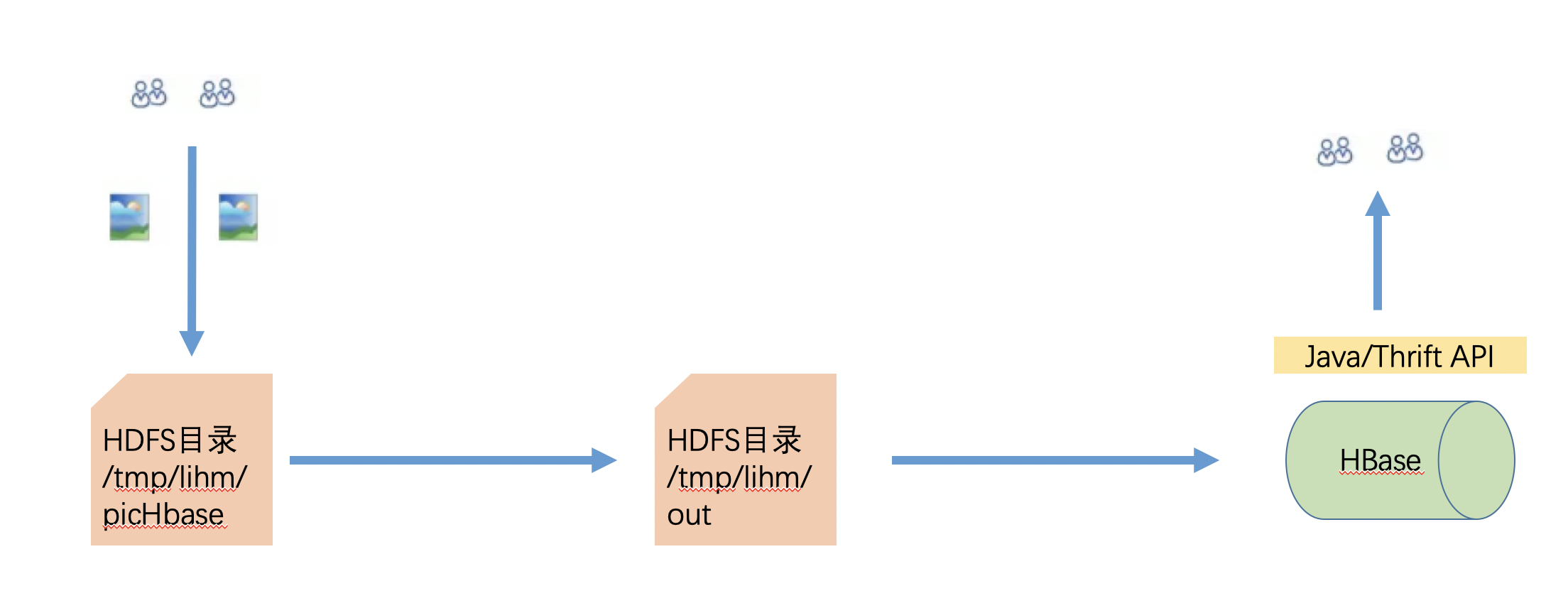
先在本地准备了一堆图片文件

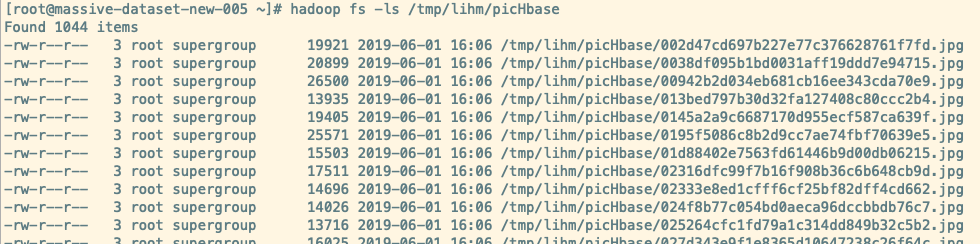
上传到 HDFS
#!/bin/bash
for i in `ls imgs`;
do
hadoop fs -put imgs/$i /tmp/lihm/picHbase
done
然后通过Java程序遍历所有图片生成一个Sequence File,然后把Sequence File入库到HBase
在入库过程中,我们读取图片文件的文件名作为Rowkey,另外将整个图片内容转为bytes存储在HBase表的一个column里。
最后可以通过Hue来进行查看图片,当然你也可以考虑对接到你自己的查询系统。
准备上传文件的 Java 代码
Maven 配置
<packaging>jar</packaging>
<name>hbase-exmaple</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
<name>Cloudera Repositories</name>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-cdh5.7.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0-cdh5.7.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
上传文件到HBase的Java代码
package cn.lihm.hbaseproj;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
/**
* @author lihm
* @date 2019-06-01 15:26
* @description TODO
*/
public class SequenceFileTest {
private static String inpath = "/tmp/lihm/picHbase";
private static String outpath = "/tmp/lihm/out";
private static SequenceFile.Writer writer = null;
/**
* 递归文件;并将文件写成SequenceFile文件
*
* @param fileSystem
* @param path
* @throws Exception
*/
public static void listFileAndWriteToSequenceFile(FileSystem fileSystem, String path) throws Exception{
final FileStatus[] listStatuses = fileSystem.listStatus(new Path(path));
for (FileStatus fileStatus : listStatuses) {
if(fileStatus.isFile()){
Text fileText = new Text(fileStatus.getPath().toString());
System.out.println(fileText.toString());
//返回一个SequenceFile.Writer实例 需要数据流和path对象 将数据写入了path对象
FSDataInputStream in = fileSystem.open(new Path(fileText.toString()));
byte[] buffer = IOUtils.toByteArray(in);
in.read(buffer);
BytesWritable value = new BytesWritable(buffer);
//写成SequenceFile文件
writer.append(fileText, value);
}
if(fileStatus.isDirectory()){
listFileAndWriteToSequenceFile(fileSystem,fileStatus.getPath().toString());
}
}
}
/**
* 将二进制流转化后的图片输出到本地
*
* @param bs 二进制图片
* @param picPath 本地路径
*/
public static void picFileOutput(byte[] bs, String picPath) {
// 将输出的二进制流转化后的图片的路径
File file = new File(picPath);
try {
FileOutputStream fos = new FileOutputStream(file);
fos.write(bs);
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 读 hbase 图片
*/
public static void readPicHBase() {
try {
Configuration hbaseConf = HBaseConfiguration.create();
// 公司 HBase 集群
hbaseConf.set("hbase.zookeeper.quorum", "100.73.12.11");
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181");
hbaseConf.set("zookeeper.znode.parent", "/hbase");
Connection connection = ConnectionFactory.createConnection(hbaseConf);
Table table = connection.getTable(TableName.valueOf("tu"));
Get get = new Get("8cd2f12410037fe73cfeb7b6a65be935.jpg".getBytes());
Result rs = table.get(get);
// 保存get result的结果,字节数组形式
byte[] bs = rs.value();
picFileOutput(bs, "/Users/tu/Public/ZaWu/picHBase/8cd2f12410037fe73cfeb7b6a65be935.jpg");
table.close();
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 将图片文件转成sequence file,然后保存到HBase
*/
public static void picToHBase() {
try {
Configuration hbaseConf = HBaseConfiguration.create();
// 公司 HBase 集群
hbaseConf.set("hbase.zookeeper.quorum", "100.73.12.11");
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181");
hbaseConf.set("zookeeper.znode.parent", "/hbase");
Connection connection = ConnectionFactory.createConnection(hbaseConf);
Table table = connection.getTable(TableName.valueOf("tu"));
// 设置读取本地磁盘文件
Configuration conf = new Configuration();
conf.addResource(new Path("/Users/tu/Public/ZaWu/conf.cloudera.yarn/core-site.xml"));
conf.addResource(new Path("/Users/tu/Public/ZaWu/conf.cloudera.yarn/yarn-site.xml"));
conf.addResource(new Path("/Users/tu/Public/ZaWu/conf.cloudera.yarn/hdfs-site.xml"));
URI uri = new URI(inpath);
FileSystem fileSystem = FileSystem.get(uri, conf,"hdfs");
// 实例化writer对象
writer = SequenceFile.createWriter(fileSystem, conf, new Path(outpath), Text.class, BytesWritable.class);
// 递归遍历文件夹,并将文件下的文件写入 sequenceFile 文件
listFileAndWriteToSequenceFile(fileSystem, inpath);
// 关闭流
org.apache.hadoop.io.IOUtils.closeStream(writer);
// 读取所有文件
URI seqURI = new URI(outpath);
FileSystem fileSystemSeq = FileSystem.get(seqURI, conf);
SequenceFile.Reader reader = new SequenceFile.Reader(fileSystemSeq, new Path(outpath), conf);
Text key = new Text();
BytesWritable val = new BytesWritable();
// key = (Text) ReflectionUtils.newInstance(reader.getKeyClass(), conf);
// val = (BytesWritable) ReflectionUtils.newInstance(reader.getValueClass(), conf);
int i = 0;
while(reader.next(key, val)){
// 读取图片文件的文件名作为 Rowkey
String temp = key.toString();
temp = temp.substring(temp.lastIndexOf("/") + 1);
// rowKey 设计
String rowKey = temp;
// String rowKey = Integer.valueOf(tmp[0])-1+"_"+Integer.valueOf(tmp[1])/2+"_"+Integer.valueOf(tmp[2])/2;
System.out.println(rowKey);
// 构造 Put
Put put = new Put(Bytes.toBytes(rowKey));
// 指定列簇名称、列修饰符、列值 temp.getBytes()
put.addColumn("picinfo".getBytes(), "content".getBytes() , val.getBytes());
table.put(put);
}
table.close();
connection.close();
org.apache.hadoop.io.IOUtils.closeStream(reader);
} catch (IOException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
picToHBase();
readPicHBase();
}
}
运行代码
首先在 HBase 中建一张表用来保存文本文件
create 'tu', 'picinfo'
注意修改代码中的配置项,如文本文件所在的 HDFS 目录,集群的 Zookeeper 地址,conf 配置路径等。
我是在本地电脑上运行的。也可以将代码打成jar包并上传到集群服务器节点。该过程略。
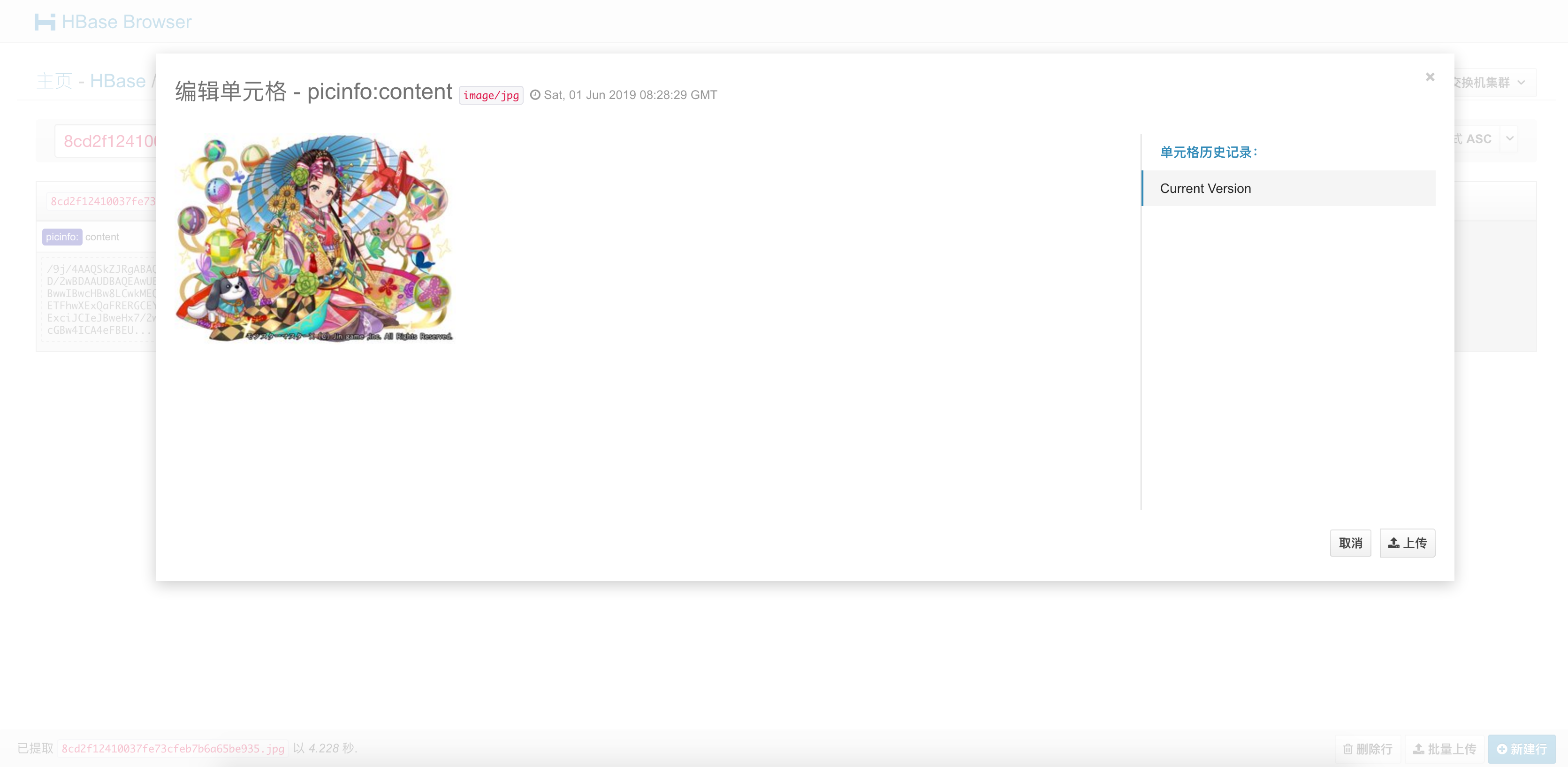
HBase 查询验证
我是将其输出到本地路径下
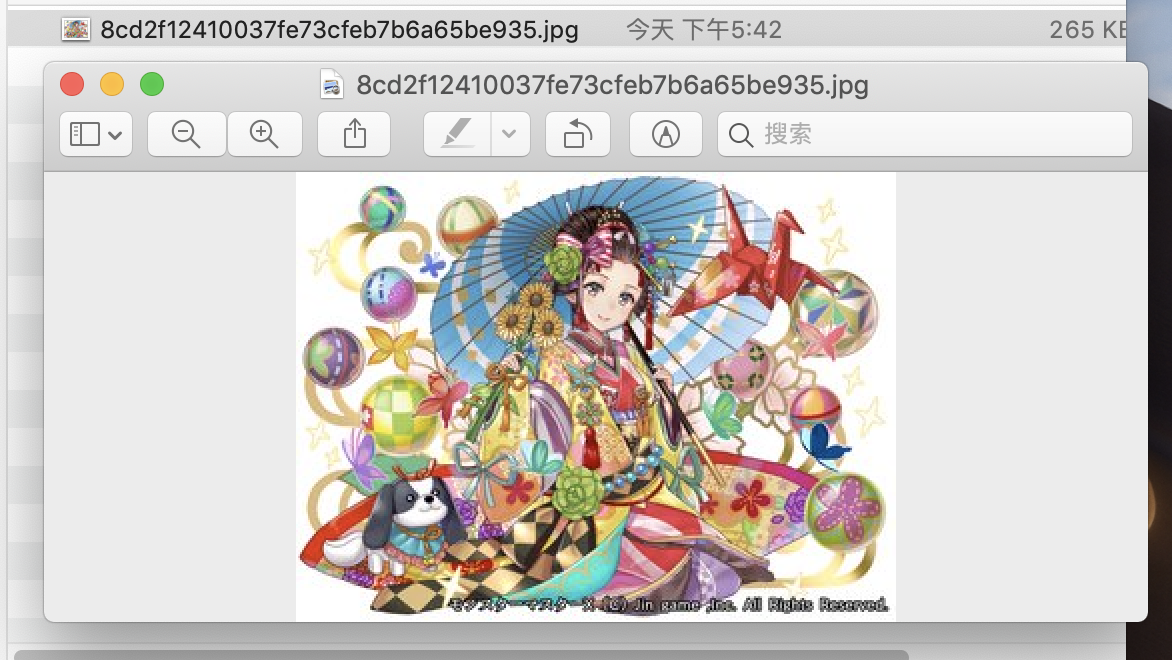
也可以用 Hue 中查询验证。
参考链接