单机搭建部署 Hadoop 、HBase
前言
之前一直是使用 CDH 。 准备入坑源码。所以想搭建一套 Apache 的来玩玩。
选择的版本:
- Hadoop: 2.7.7
- HBase: 1.2.11
- Linux: CentOs 6.5
- JDK: jdk1.8.0_161
准备
安装jdk,配置环境变量。 这个网上很多,自行百度。
Hadoop、HBase tar包去官方网站下载即可
下载之后将其解压。
配置 Hadoop 环境变量
1. 配置hadoop-env.sh、yarn-env.sh
在Hadoop安装目录下 etc/hadoop
在 hadoop-env.sh、yarn-env.sh
加入 export JAVA_HOME=/usr/local/jdk1.8.0_161(jdk安装路径)
保存退出
2. 配置HADOOP_HOME
修改全局环境变量
在 /etc/profile
export HADOOP_HOME=/opt/hadoop-2.7.3 # Hadoop的安装路径
export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
配置基本相关xml
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>数据需要备份的数量,不能大于集群的机器数量,默认为3</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/dfs/nn</value>
<description>namenode上存储hdfs名字空间元数据</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/dfs/dn</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>localhost:9001</value>
<description>SecondaryNameNode HTTP 端口。如端口为 0,服务器将在自由端口启动。</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
<description>设置为true,可以在浏览器中IP+port查看</description>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>mapreduce运用了yarn框架,设置name为yarn</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>localhost:10020</value>
<description>历史服务器,查看Mapreduce作业记录</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>localhost:19888</value>
<description>MapReduce JobHistory Web 应用程序 HTTP 端口</description>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager上运行的附属服务,用于运行mapreduce</description>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
<description>MapReduce JobHistory Web 应用程序 HTTP 端口</description>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:8032</value>
<description>ResourceManager 对客户端暴露的地址</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>localhost:8030</value>
<description>ResourceManager 对ApplicationMaster暴露的地址</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>localhost:8031</value>
<description>ResourceManager 对NodeManager暴露的地址</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>localhost:8033</value>
<description>ResourceManager 对管理员暴露的地址</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>localhost:8088</value>
<description>ResourceManager 对外web暴露的地址,可在浏览器查看</description>
</property>
</configuration>
Hadoop的启动与停止
1. 格式化namenode
bin/hadoop namenode -format
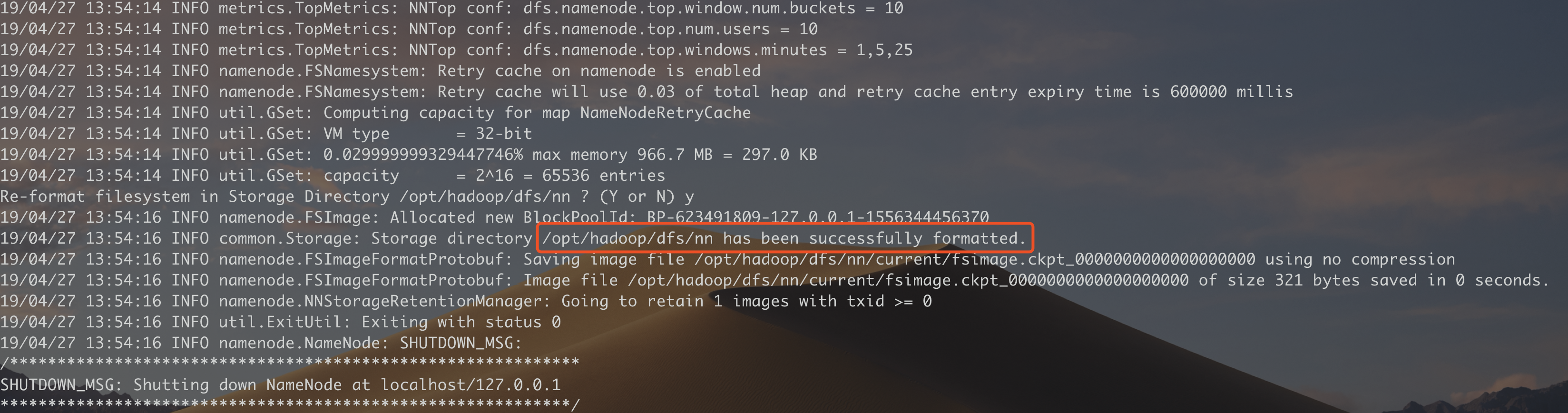
出现 successfully formatted 即可
2. 启动 HDFS、YARN
一起启动
sbin/start-all.sh
也可以分开启动
sbin/start-dfs.sh
sbin/start-yarn.sh
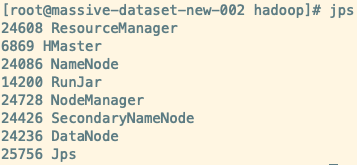
3. 验证
在命令行输入 jps 可以看到启动的 Java 进程,接着在看看是否有 HDFS、Yarn 的角色
在浏览器中输入http://{ip}:50070 查看 NameNode 状态。 ip 为你安装的机器 IP
4. 停止
停止hadoop,进入Hadoop目录下,输入命令:
sbin/stop-all.sh。
同样也可以分开停止的。
sbin/stop-dfs.sh
sbin/stop-yarn.sh
HBase
1. 配置HADOOP_HOME
在 /etc/profile 中加入
export HBASE_HOME=/opt/hbase-1.2.11
export PATH=$HBASE_HOME/bin:$PATH
2. hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:8020/hbase</value>
<!-- 端口要和Hadoop的fs.defaultFS端口一致-->
<!-- hbase存放数据目录 -->
</property>
<property>
<name>hbase.cluster.distributed</name> <!-- 是否分布式部署 -->
<value>false</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/hadoop/hbase/tmp</value>
<description>hbase临时文件目录</description>
</property>
<property>
<name>hbase.zookeeper.quorum</name> <!-- list of zookooper -->
<value>localhost</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/hadoop/hbase/zookeeper</value>
<description>zookooper配置、日志等的存储位置</description>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
</configuration>
3. hbase-env.sh
使用 HBase 自带的zookeeper
export HBASE_MANAGES_ZK=true
指定 JDK
export JAVA_HOME=/usr/local/jdk1.8.0_161(jdk安装路径)
启动与停止Hbase
在Hadoop已经启动成功的基础上,输入 start-hbase.sh ,过几秒钟便启动完成。
输入jps命令查看进程是否启动成功,若 机器 上出现 HMaster 即可。 (不知道为什么。我这里没有出现 HQuorumPeer,不知道是不是版本的原因)
输入 hbase 可以看到支持的命令服务。 zkcli 是进入 HBase 自带的 zk 的命令
输入 hbase shell 命令 进入 HBase 命令模式
在浏览器中输入http://{ip}:16010 就可以在界面上看到 HBase 的配置了
当要停止hbase时输入stop-hbase.sh,过几秒后hbase就会被停止了。
总结
这只是简易版的。生产环境的要求肯定不止这些。参考者请注意。
这里有个地方没弄懂。尝试过配置 HBase Master 的端口为 16000。 发现未生效。端口是随机的。。。 没想明白为什么。等看下源码找找原因。
附上 HBase 端口设置参数
hbase-site.xml
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.regionserver.port</name>
<value>16201</value>
</property>
<property>
<name>hbase.regionserver.info.port</name>
<value>16301</value>
</property>
参考链接