记 Spark 打包放到 Hadoop 集群运行踩坑
前言
因近期有写 使用 Spark 通过 BulkLoad 快速导入数据到 HBase 的需求。
在写过程中用 maven 打包一直失败。导致我无法测试自己的代码
折腾了一晚上终于踩坑完毕了
开发环境
操作系统:MAC
Scala:2.10.5
Maven: 3.3.9
Spark: 1.6.3
构建
在 IDEA 上新建 scala 项目。怎么构建的就不细说了。网上很多。如何在Java Maven工程中编写Scala代码
目录结构如图所示。记得给 scala 文件夹加上 source ,让其变成蓝色
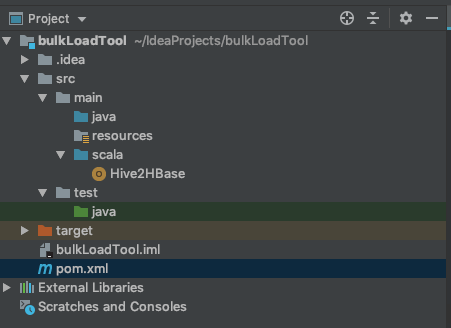
新建一个 object
object Hive2HBase {
def main(args: Array[String]): Unit = {
print("lihm")
}
}
修改 pom.xml
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>2.10.5</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
</plugins>
</build>
scalaVersion 我猜是 打包编译时指定的 scala 版本
这种 xml 配置打包的话是不会将依赖打成jar包的
在 plugins 下追加一个 plugin
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
打包
在项目的顶级目录下执行下方命令打包
mvn clean scala:compile compile package -DskipTests=true
# 忽略此命令
# -Dscala.version 表示你打包时的编译版本。建议跟自己本机安装的相同
# mvn clean package -Dscala.version=2.10.5
scala:compile 表示编译 scala 文件
compile 表示编译 Java 文件
-DskipTests=true 表示跳过编译时的测试
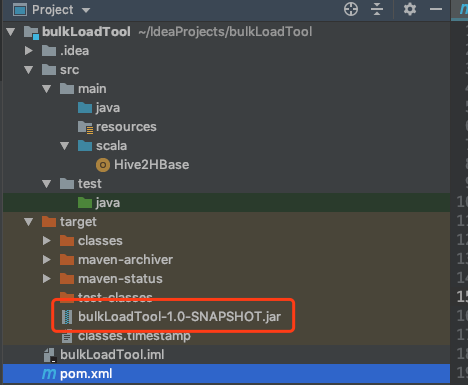
打包完成之后可以在 项目的 target 文件夹下看到打包好的 jar 文件
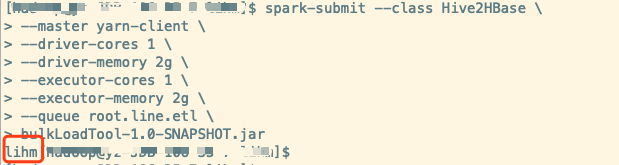
示例运行
将编译好的 jar 包上传至服务器,使用spark-submit提交
export HADOOP_USER_NAME=hbase
spark-submit --class Hive2HBase \
--master yarn-client \
--driver-memory 2g \
--executor-cores 1 \
--num-executors 200 \
--executor-memory 2g \
--queue root.line.etl \
bulkLoadTool-1.0-SNAPSHOT.jar
–driver-memory 指定driver的内存
–class 是指定运行的主类。如果有路径,就把路径补全
–num-executors 是指定 executor 个数
–executor-memory 每个 executor 的内存
–queue 是指定提交时的队列。如果你的 yarn 没有资源队列限制就可以去掉。
总结
最先开始打包失败时一度以为时maven 的问题。配置 maven 就折腾了好久
最后实在没办法了,怀疑是不是打包命令的问题。找到一个 github issue 看到有人建议 -Dscala.version 。 尝试后发现可行。才踩坑完毕
再记:
忽略的那个命令为最先成功的命令,接着开发过程中我发现该命令报错。
接着又找到一个能编译打包并且成功的命令。
先用着,如果后续弄明白了再补上。
参考链接